written by Alex Stocks on 2016/03/05,版权所有,无授权不得转载
Redis是目前一种比较流行的内存数据库,但是其缺点也非常明显:
1 Scale up能力
Redis采用了单进程架构,无法利用服务端多核的高性能,进而制约了其对服务器超大内存的使用能力。Redis能够使用的内存极限容量经验值为【8G, 24G】,超过这个容量上限其性能便急剧下降。
2 Scale out能力
基于Redis的cluster目前采用了两种设计模式:proxy based和无中心的smart client based(如官方的Redis 3.0)。官方实现的Redis Cluster把系统设计成了一个All-In-Box
模式的cluster,看似简洁易用轻便很多,其实不过是多个模块应该执行的任务混合在一起让一个Redis执行了,看似平等的一模一样的Redis进程的逻辑变得很复杂起来,一旦出问题就是一堆乱麻,你就只能呵呵哒了。目前业界暂时没有关于Redis 3.0的比较成功的使用案例。
Proxy-based Redis Cluster看似让架构复杂很多,但是这种架构很容易做到让每个模块自身职责明了清晰且分工明确,尽可能专注于符合自己职责的工作,每个模块可以独立部署升级,所以运维也就方便很多,契合微服务的精神。目前比较成功的proxy有twemproxy,比较方便使用的Redis Cluster有Codis等。
目前各种Iaas层的云架构方兴未艾,OpenStack是目前最成功的架构中的一个,其特点之一便是能够构建一个提供多租户使用的公有云系统。不管是否基于公有云系统,如果想要构建一个多租户的Paas层的多租户的内存文件系统服务,囿于个人孤陋寡闻,目前还未见到比较成熟的相关系统。
磁盘文件系统最基本的的组织单元之一如扇区,其size一般固定为512B,基于扇区就可以构建4kB或者8kB等size的磁盘簇等多粒度存储单元,如果要构建一个内存文件系统,也可以基于类似的方式构建一个多粒度的内存文件系统。
Redis自身具有db的概念,即一个redis instance可以从逻辑上划分多个db分别给不同的用户使用,每个用户的数据从逻辑层面来看是相互隔离的,但是其缺点之一就是Redis不提供每个db占用的内存空间的size,更不能限制其内存使用量,用户一般能做的就是限制Redis instance自身占用的内存总量。
Redis还有一个优点,可以通过master与slave构成一对Redis instance保证数据的consistency。但是这种一致性是一种最终一致性,并不能算是强一致性,即master处理一个写请求后,写请求的数据何时会被同步给slave且能让slave落盘成功,用户无法知晓。
一般的分布式文件系统可以基于data version来解决强一致性问题,但是Redis自身并不提供这种能力。在一个proxy based的系统中,proxy一般只承担数据请求的转发能力,为了保证用户写请求的强一致,可以进一步提高proxy的能力:区分读写请求和读写分离能力。
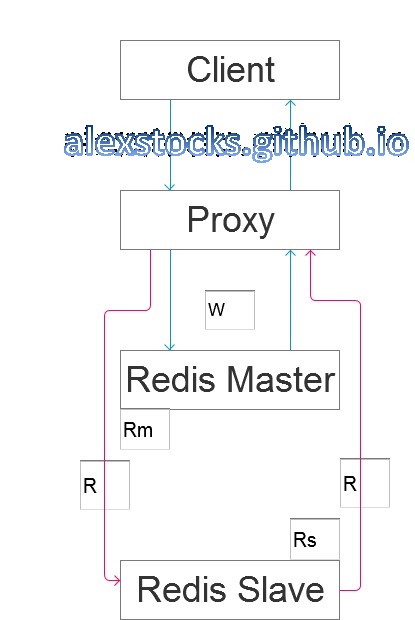
假设有一个简单的proxy based的系统如下所示:
Proxy通过区分读写请求和读从写主的能力,如果要保证数据的强一致性,一个client的写流程如下:
如果client读到的value与写入的value一致,便可以认为写成功了,否则认为是失败的,不管其原因是Rm与Rs的同步太慢还是中间整个流程耗时过长导致了请求超时。如果某个Redis的写操作被认为是幂等的,则用户可以通过重试上面的流程来提高写成功率。这个方案需要redis和proxy配合一起保证数据的强一致性。
还有一种选择。proxy可以向Rm发送info命令,可以得到其sync buffer的offset值masterreploffset,依据写请求前后两个不同的offset值,大致地可以把上面的流程修改为:
以上两种方法各有优劣,分别适用不同的场景,用户自己取舍。如果是面向用户的服务,则采用方案一,proxy的任务轻便一些,如果是Redis Cluster内部的Redis另有它用(下面讲到的架构),则可以使用方案二。
另外,为了加快主从同步速度,建议关闭Rm的磁盘写能力,只让Rs开启磁盘存储能力。
基于前面的分析,我手绘了一个Redis Cluster架构图如下:
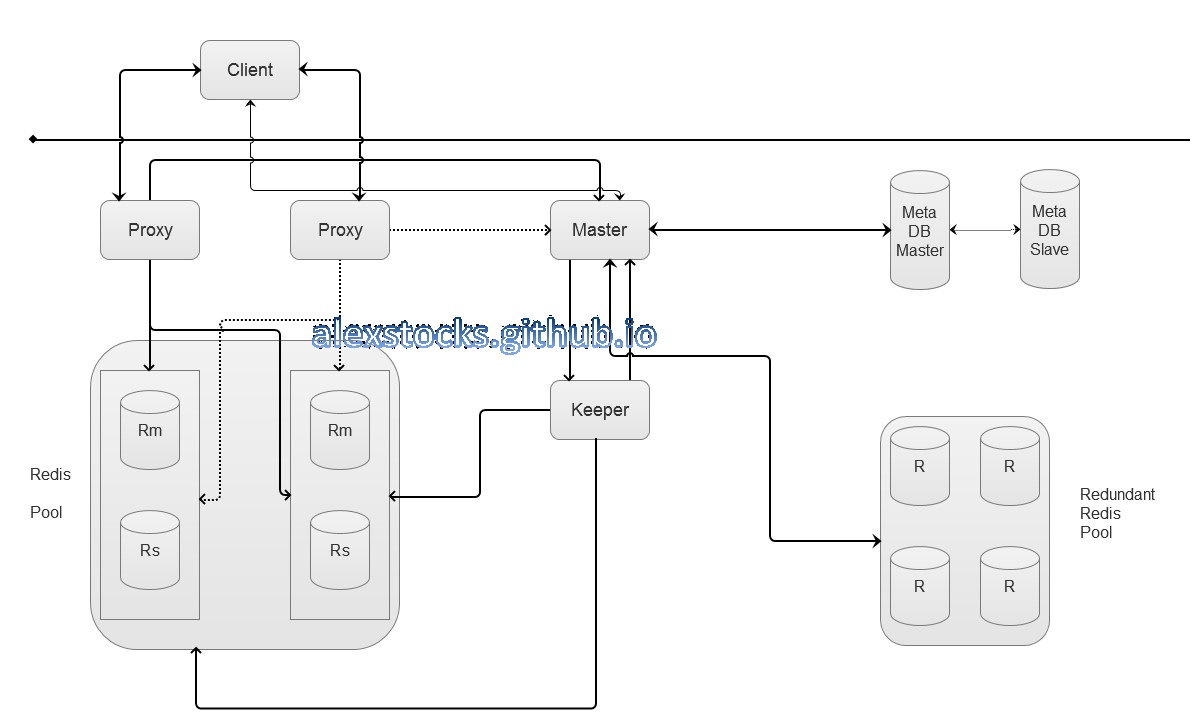
为了综述方便,我不再详细解释cluster内部的详细流程,只分别介绍各个model的职责。
Proxy处于cluster的代理层,其职责是:
1 资源池子中某个redis Instance对的主从切换消息;
2 发生主从后的新的Rs消息;
3 新注册的用户以及其使用的资源消息;
4 用户资源更改消息;
5 用户被删除消息;
6 用户使用的资源超出其粒度(quota)的消息;
7 封禁某个db响应写请求的消息;
Keeper作为master的管家,具有管理Redis Pool的能力,其职责列表如下:
metadb作为meta信息的存储者,其能力列表如下:
master作为整个cluster内的管理者,其职责列表如下:
1 向各个proxy发出对某个db的写请求访问封禁通知;
2 收到所有的proxy响应后,从备用资源池抽出合适粒度的instance上的db,作为migrate命令的参数发给keeper;
3 根据keeper操作结果,修改metadb中db的相关信息;
4 命令keeper对原db做出drop操作;
5 通知各个proxy修改redis pool架构信息并开放对某个db的写请求访问;
6 返回成功或者失败信息给user。
上面的流程设计是假设Redis被部署于物理机之上,如果想要把Redis Instance部署在公有云系统之上呢?
上面的架构图是基于Redis被部署于物理机之上这个条件设计出来的,所以附带了一个Redundant Redis Pool以应对Redis Instance failover的情况。如果整个系统能部署于openstack云系统之上,或者至少能否把Redis部署于docker集群之中,这个Redundant Redis Pool就完全没有存在的必要了。
因为docker容器启动速度是如此之快,所以一个备用池子就没有存在的必要了。当出现failover的情况的时候,master向云系统的管理者nova或者其职责相当的角色发送启动命令以及相关的参数,待容器启动成功之后把它交个keeper就可以了,其他流程不用修改。
有没有想过,master可能是系统的单点?更别提keeper了。
一种处理方法就是更改频繁的系统状态数据放在metadb之中,让master做到无状态,只是执行相关的逻辑任务即可,这样就解放了master和keeper,就算是他们崩溃掉也无谓,重启即可,至于在同一个机器或者不同的机器重启都无所谓,用keepalived或者dns系统保证其地址不变即可。而且他们的任务并不繁重,所以更不必担心其通信数据量多少的问题。
那么,metadb究竟使用何种db为宜呢?使用Mysql抑或是MongoDB或者是其他更高大上的系统?其实metadb存储的数据量不多,当系统出现不稳定情况的时候,就得快速响应master的数据请求,而且系统的状态这种更新频繁的数据也由它负责存储,metadb也用Redis充当即可。但是需要注意的是,master每次修改响应数据的时候,都要保证数据的强一致性,至于操作步骤可以参考第三章节。
上面的架构图以及相关的流程都讲到master需要和proxy以及keeper进行通信以完成相关系统任务以及Redis Instance状态的流转,但是他们之间究竟如何通信呢?最简单的情况,他们之间以最基础的tcp方式完成通信任务,但是开发时间就浪费在解包封包(pack/unpack)的任务上了。
更进一步,metadb既然使用了Redis,是不是可以借用Redis的pub/sub能力?至于如何进行,自己稍微想想就能明白。至于通信中使用的message可以借助protobuf这种成熟的IDL语言描述之,以减轻工作量。
至于metadb自身的稳定性,本文就不再赘述了_。或者你有更好的方式处理之,总之是合适够用即可。
这个系统的特点就在于多用户和多粒度。
metaserver与metadb构成的子系统以满足分布式系统CAP中的CP为主,而client-proxy-redis instance子系统如果不考虑读写分离特性的话以满足AP为主。
本文没有列明metaserver的操作流程,其与proxy以及keeper之间的操作本质是二阶段提交过程而已。
proxy的操作其实还应该列明过载保护特性,如内存、网络带宽等资源的保护,系统实现过程中我会对文档逐步作以补充。

|

|
- 于雨氏,2016/03/05,于金箱堂。
- 于雨氏,2016/03/19,于金箱堂补充第6章。