written by Alex Stocks on 2018/11/17,版权所有,无授权不得转载
据说 现代医学即始于听诊器的发明【见参考文档1】,医生借助此器物得以 收集和放大从心脏、肺部、动脉、静脉和其他内脏器官处发出的声音见参考文档1.
一个摆脱了手工作坊时代的可称之为近代化的互联网公司,如果想对自己的后台服务以及各个用户的客户端的运行情况了如指掌,大概也需要自己的 “听诊器”:分布式实时监控告警系统、分布式日志收集系统和分布式链路追踪系统。实时监控告警系统用于获取当前服务端的运行情况,当某服务的某个指标波动超过正常阈值时进行警报提示,以及时止损。借助日志收集系统可以获取某个事故的上下文环境,以明晰问题所在。链路追踪系统则可以跟踪一次服务流程的完整过程,可以帮助分析影响服务质量的瓶颈所在。
愚人刚入职当前公司的时候,这三套设施近乎于无。去年(2017年)在公司做了一套消息系统时,顺便基于 Flume/Kafka/Elastisearch 搭建了一套简易的日志追踪系统,直到昨晚为止相关业务方自己流程出问题时还在借助这套系统提供的消息日志对自己服务的问题进行分析,监控系统则是用自己实现的消息发送和接收两个 Robot 对各个消息子链路的消息时延进行追踪计算后汇总到微信中进行人工监控。此后便借助公司的各种机缘逐步搭建了监控告警系统和日志收集系统。
闲话休说,言归正传。去年(2017年) 12 月份某同事给聊天室上线了某新功能后便去休假了,翌日便有聊天室用户反馈收不到消息,估计这位同事此时正在火车上欣赏窗外祖国的大好河山,由于手机联网能力太差无法及时处理,留守公司的同事也无法根据线上日志追查到底是那台服务进程发生了故障,最终的解决方法是把 70 多个服务进程逐一重启以恢复服务。此事大概稍微引起了公司领导对基础设施的重视,可能想起来鄙人以前一直叨叨要有这样一套系统,便嘱托鄙人有时间研究下。可能是这种事故太多领导已经麻木了,也可能是因为工作繁忙此事此后便不再提及了。
系统就这么继续 “安稳” 地继续运行了俩月,一个总监忙着设计了一套完全与现有服务端架构不兼容的 “新架构”,待图片绘就和文字码完后,打算给小弟们分配相关开发任务。清晰地记得2018年1月底一个周六下午,两个服务端总监【高级总监和总监】招呼愚人开会,而后大概 15 分钟内滔滔不绝地说了当前架构的各种不足以及新架构的各种牛逼之处,在第 15 分钟时 CTO 冲进会议室,愠怒道某服务又挂了,此后俩总监跑出去商量对策。鄙人便又在会议室待了大概二十分钟后,俩总监垂头丧气地回来说是不知道服务问题到底出在何处,只好重启了事,其中一位便发话道:你赶紧把监控系统做了吧!
监控告警系统便这样立项了。
诚如武器有 “苏式” 和 “欧美式”,监控系统也有很多风格地实现,国内业界数的着的大公司各家成长路线不一样,对同一系统的实现风格也不一样。不仅各大公司的技术实现路线不一样,即使同一个公司内不同事业群的技术实现路线也不一样,正如 参考文档2 中一句话:每个事业群均根据自身特性自主研发了多套监控系统,以满足自身特定业务场景的监控需求,如广告的GoldenEye、菜鸟的棱镜、阿里云的天基、蚂蚁的金融云(基于XFlush)、中间件的EagleEye等,这些监控系统均有各自的使用场景。。
阿里如此,腾讯也不例外。参考文档3 给出了微信刚起家时的监控系统的实现:
1.申请日志上报资源;
2.在业务逻辑中加入日志上报点,日志会被每台机器上的agent收集并上传到统计中心;
3.开发统计代码;
4.实现统计监控页面。这种套路的系统的缺点,参考文档2 文中有道是:这种费时费力的模式会反过来降低开发人员对加入业务监控的积极性,每次故障后,是由 QA 牵头出一份故障报告,着重点是对故障影响的评估和故障定级,此文稍后便提及 出乎意料地简单且强大的公司内的标杆——即通后台(QQ 后台) 的监控告警系统:
这套称之为 基于 ID-Value 的监控告警体系 的实现思路非常简单,客户端 SDK 仅提供了 2 个 API,其特点在于:数据足够轻量 且 数据是客户端主动向监控中心 Push【迥异于 Prometheus 的服务端向客户端 Pull metrics指标】。经个人搜索,在淘宝的开源代码平台上搜出来的如下腾讯代码即为腾讯内部 API 接口的头文件:
// http://code.taobao.org/p/rockysmarthome/diff/2/trunk/smarthome/EHNetwork/svrlibindevelop/include/utility/attrapi.h
#ifndef ATTR_API_H
#define ATTR_API_H
/**
* <p>提供监控打点的API,其共享内存地址为0x5FEB,一台机器上监控打点的属性个数最多为1000个</p>
* <p>20011-11 修改</p>
* @author joepi
*/
#define MAX_ATTR_NODE 1000
#define VERSION "1.1(增加版本信息与取值 )"
typedef struct
{
int iUse;
int iAttrID;
int iCurValue;
} AttrNode;
typedef struct
{
AttrNode astNode[MAX_ATTR_NODE];
} AttrList;
/**
* 累加属性所对应的值
* @param attr 属性值
* @iValue 属性对应的累加值
* @return 0 成功 -1失败,失败的原因是本机器上打点的属性个数超过了1000
*/
int Attr_API(int attr,int iValue);//iValue为累加值
/**
* 直接设置属性所对应的值
* @param attr 监控打点的属性值
* @iValue 属性对应的值
* @return 0 成功 -1失败,失败的原因是本机器上打点的属性个数超过了1000
*/
int Attr_API_Set(int attr,int iValue);
/**
* 得到监控打点属性所对应的值
* @param attr 监控打点的属性
* @param iValue 如果属性存在,或者属性不存在(此时认为值为0),但是新分配成功,值将赋值给iValue
* @return 0 属性找到了, 1属性没找到但是新分配了 -1属性没找到并且也没有新分配成功
*/
int Get_Attr_Value(int attr,int *iValue);//获得属性ID为attr的值,如果不存在返回-1,存在返回0并附给iValue;
int Attr_API_Get(int attr,int *iValue);//获得属性ID为attr的值,如果不存在返回-1,存在返回0并附给iValue;
#endif上面代码中最重要的两个接口分别是 Attr_API 和 Attr_API_Set,分别称之为 累加属性值上报 和 设置属性值上报。最经常使用的是 累加属性值上报 ,其意义也非常明了:如果监控系统的实时时间单位是分钟级,则把每分钟内对此 ATTR 上报的所有值进行累加,而后作为分钟时刻的监控值。 设置属性值上报 的意义则是:以每分钟内第一个上报值作为此分钟时刻的上报值,其使用主要集中在一些统计采样分析任务场景下。
这套系统的工作流程如下:
- 1 申请者在操作后台(可以称之为 Console)上提供一段字符串描述后,Console 为这个文字描述分配一个数值作为其 ID,同时配置好告警条件;
- 2 申请者在要被监控的业务流程代码中调用监控 API,在上面代码中 @attr 字段填充为 Console 分配的 ID,把 @iValue 设置为上报值(Attr_API 中这个值一般设置为 1);
- 3 系统运行时 SDK 会在申请者推设置的两个参数值外再添加上机器 host 和精确到纳秒的当前时刻值以及其他上下文信息后写入一个基于共享内存实现的环形队列;
- 4 每台机器上的 Agent 定时将所有 ID-Value 上报到监控中心;
- 5 监控中心对数据汇总入库后就可以通过统一的监控页面输出监控曲线;
- 6 监控中心通过预先配置的监控规则产生报警。上面流程道出了监控系统的两大用途:以图形曲线显示系统运行情况,对服务进行报警。参考文档3 指出了这套系统的进一步使用:在少量灰度阶段就能直接通过监控曲线了解业务是否符合预期。
诚所谓“筚路蓝缕,以启山林”,QQ 的系统作为前辈在前面树立了标杆,吾辈参照其原理实现一套类似的系统就是了。
愚人去年通过公开渠道搜集了这套系统的相关资料进行理解后,便自己设计了一套类似系统的架构实现,当项目立项开工时相关准备工作已经完成,最后在农历2018年新年前夕共用三周时间便完成了系统的原型开发。
描述监控告警系统之前,先对监控的对象进行一番剖析。
开发一套业务系统时,其架构师或者设计者在思虑其实现细节之前,会先对其进行拆分成各个子模块,然后再考虑各个子模块的实现。业务系统上线时,相同的子模块会被部署在多个服务节点上。有的公司以 Host IP 标识每个服务节点,但若这个节点是个虚机,则其 IP 会漂移,二者之间并非一一对应关系,故而用 Host IP 并不合适,可以统一给每个服务节点分配一个 ID。
监控告警系统对整个业务系统称之为 Service,对各个子模块称之为 Attribute(缩写为 Attr),每个服务节点则称为 ServerID。
第一章曾描述 QQ 后台有两种数据上报类型 累加属性值上报 和 设置属性值上报,并分别设置了两个 API 以示区别。实际的线上系统这两种类型许是不能满足要求的,可能需要更多的计算类型,譬如一个监控时段(AlarmTime,本系统的监控时段为分钟)内某指标的 最大值/最小值/平均值 等, 监控系统称之为监控类型(AlarmType)。监控系统收集各个指标时应该获取其 AlarmType。
监控告警系统的最终计算结果(Metrics)是以 KV 形式存储和展示的,根据上面对业务系统的分析,最终一个监控指标的 Key 应是 Service + Attr + AlarmType + AlarmTime + ServerID,其 Value 即为监控统计值。
考虑到某个 Attr 会在多个服务节点上部署,监控告警系统使用者常常需要知道所有节点上某个监控指标的总量,并基于总量对系统当前的服务能力进行分析,这种总量形式的监控指标的 Key 是 Service + Attr + AlarmType + AlarmTime,其 Value = ∑(Service + Attr + AlarmType + AlarmTime + ServerIDi, i = 1, 2, …, n),n 为服务节点总数。
参考系统5 对监控追踪一类的运维系统提出了三个设计目标:
- 1 低消耗
即运维系统须高度简洁,不能对业务系统地运行造成影响。
- 2 对应用透明【或称之为无侵入、无埋点】
业务开发人员在开发过程中无需关注运维系统。
- 3 可扩展
结合上面对监控对象的建模,本系统无法做到 对应用透明,业务使用方须调用 API 对系统进行埋点监控。至于 低消耗 和 可扩展,则是对代码开发质量以及系统架构设计的要求,本系统还是能做到的。
Monitor 系统不是万能的,不可能在设计之初把所有的监控类型都涉及到。
AlarmType 的本质就是多种计算算子,随着应用系统的广泛使用,可能需要更多的 AlarmType,此时有两种解决方法。第一种解决方法就是升级系统,第二种方法则是基于现有的监控系统的基本 AlarmType 之上组合出更多的 AlarmType。
譬如欲计算某服务整个处理流程的耗时(TimeSpan),则可以在发送请求(Client Send)时记录起始时间值 StartTimestamp,接收到响应(Client Receive)时记录结束时间值 EndTimestamp,则 TimeSpan = EndTimestamp - StartTimestamp,然后把 TimeSpan 作为一个 Value 进行上传。通过在业务使用时进行这种变通的计算方式尽量减少监控系统升级的可能性。
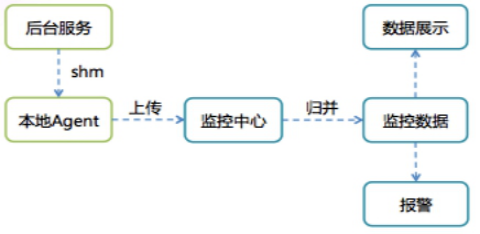
参考文档1 中描述 听诊器由听诊头、导音管、耳挂组成,听诊器与医生构成了一套器人复合诊断系统。其实告警监控系统(下文称之为 Monitor)与这个复合体基本无差,其由数据采集节点(Client)、监控代理(Agent)、数据传输节点(Proxy)、计算中心(Judger)、存储节点(Database)、展示中心(Dashboard)、控制中心(Console)、告警中心(Alarm)和注册中心(Registry)等部分构成。
本系统考虑到公司业务跨 IDC 特点,其总体架构如下:
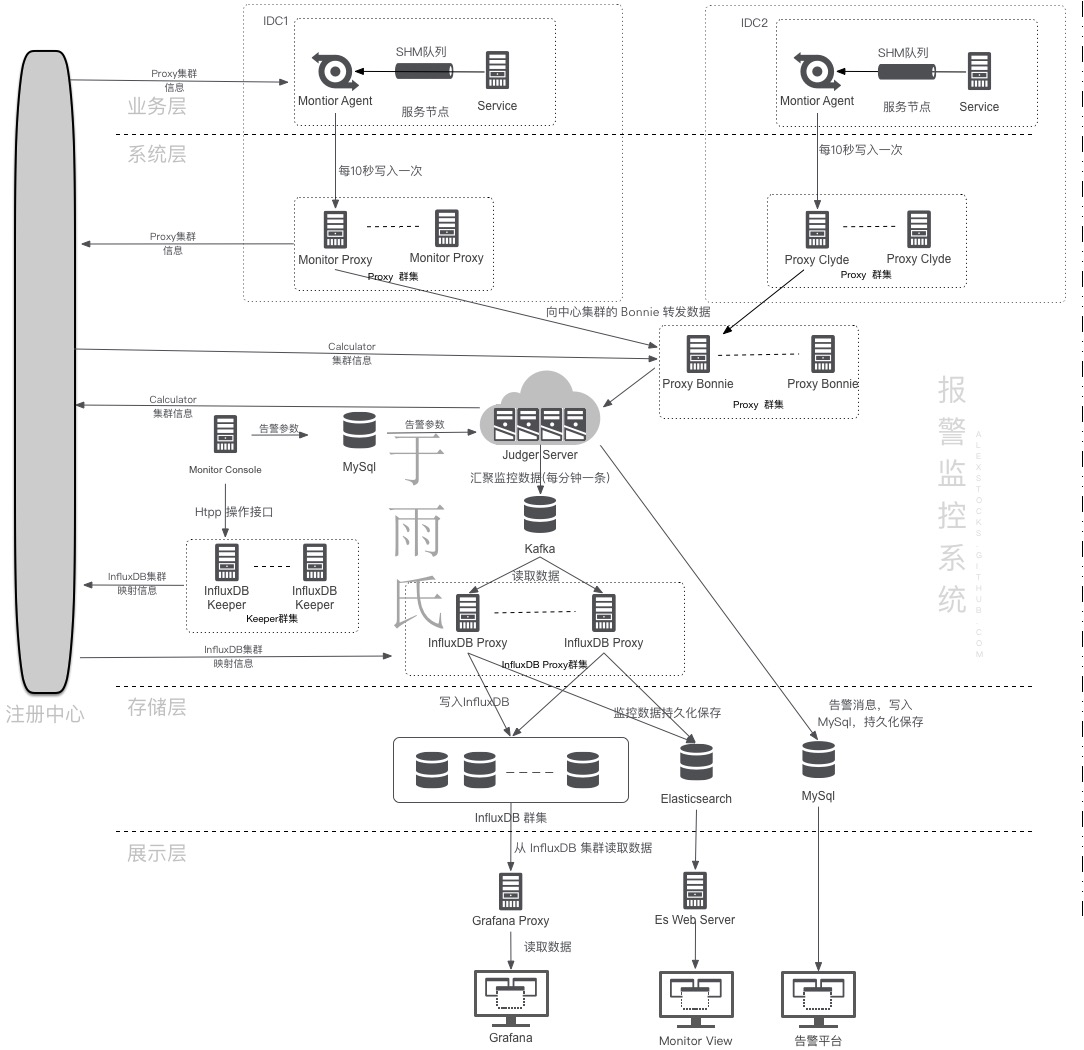
下面分别依据介绍各个子模块的功能。
1 Client 是上报数据流的源头,通过调用 Monitor SDK 代码预埋监控点,在程序运行时上报数据到本机的 Agent。
Client 是服务端的服务节点,因为其调用了 Monitor 的服务,故而称之为 Client,不要与常用的 APP 引用混淆。
2 Agent 从 SHM 队列中接收 Client 上报数据,进行规整聚合(Aggravation)后定时上报给监控中心。
Agent 对原始上报数据进行了第一次初步加工,其目的是减少 Judger 模块的计算量,并减少网络通信量。
3 Proxy 是数据传输通道,从 Agent 或者外部 IDC 的 Proxy 传输来的监控流量包,把数据传输给 Calculator。
Proxy有两种工作模式:工作的计算节点所在 IDC(称之为 Monitor Center)的 Bonnie 和工作在所有业务机房的 Clyde,二者都是跨 IDC 的 Monitor 系统的数据传输代理,本身无状态。
每个 IDC 的 Clyde 群集向自己所在机房的 Registry 注册,然后每个服务节点的 Agent 采用随机的路由策略把监控数据网络包发给某个固定的 Clyde 节点。
Monitor 所在机房的 Proxy 称之为 Bonie,它向 Monitor 所在 IDC 的 Registry 注册,Clyde 采用随机路由策略把上报数据均衡地发送给 Bonie 群集中某个 Bonie Proxy,Bonie 收到数据后根据 Service 字段发送给其对应的 Judger。
Clyde 和 Bonie 是上世纪 30 年代米国大萧条时期的一对雌雄大盗。
4 Registry 是一个分布式的注册中心,提供服务注册、服务发现和服务通知服务,实际采用当下被广泛使用的 Zookeeper,每个 IDC 单独部署一套 Registry,Proxy/Judger 都需要按照约定的 schema 规则向Registry注册。
5 Judger 是 Monitor 系统的中枢所在,对上报的原始数据进行第二次加工然后存入本地 DB,并根据预设的规则进行告警判断。
Judger 存储一段时间内的监控数据,最终各种计算结果存入 Database 中,所以其是弱状态的服务节点,所有 Service 的监控数据都会从Proxy 集中路由到某个固定的 Judger,Service 与 Judger 之间的映射关系可在 Console 上设定,并存入 Database 和 Registry 中。
6 Database 作为归并计算后的监控数据的最终目的地,本系统使用 Elasticsearch/InfluxDB/Mysql 多种开源组件。在 Mysql 中存储告警参数以及告警结果,在 InfluxDB 中存储归并后的结果,归并前的原始结果则在 Elasticsearch 中落地。
注:本系统把告警原始结果存储 Elasticsearch 中是合适的,因为公司体量并不大,Monitor 把所有的原始上报结果以 day 为单位汇总存入一个 Elasticsearch index。如果数据量非常大,可以考虑存入 HDFS。
7 Console 用于设定 Monitor 的告警规则,并把相应规则存入Mysql alarm table中。
8 Dashboard 用于用于展示从某个维度加工后的监控数据,本系统采用 Grafana 作为展示 Panel。
9 Alarm 顾名思义就是 Monitor 的告警系统,它依据 Judger 处理的告警判断结果,把告警内容以短信、邮件等形式推送给相关人员。
Monitor 作为一个业务告警监控系统,其自身的运行 Metrics 亦须予以收集,以防止因为其自身故障引起误报警。Agent/Proxy/Judger 定时地把自身的 qps、监控数据量等参数设定在 MySQL monitor db 里,Console 可以查看到这些 metrics 数据。运维人员可以在 Console 中设定一些规则对 Monitor 进行监控,其定时地汇总出一个 Monitor 运行报表通过邮件方式通知相关人员。Console 还需要监控 Registry 中各个 Schema 路径,当某个 Monitor 系统节点宕机时发出最高级别的告警。Console 相当于 Monitor 系统的监控者。
第二章介绍了 Monitor 系统的总体设计,本章分列多个小节详述愚人的架构方案的各个子系统相关实现。
Console 用于告警参数设置,以及新服务上线时候通知某 Judger 由其负责某服务的相关计算。
Console 系统并不追求并发性能,只是作为 Monitor 系统的控制中心,其功能比较繁复,罗列如下:

> 角色与数据库中的 “角色” 概念一样,不同角色可以查看的不同的服务。Console 给真实用户分配权限,为其绑定不同的 角色 即可。 
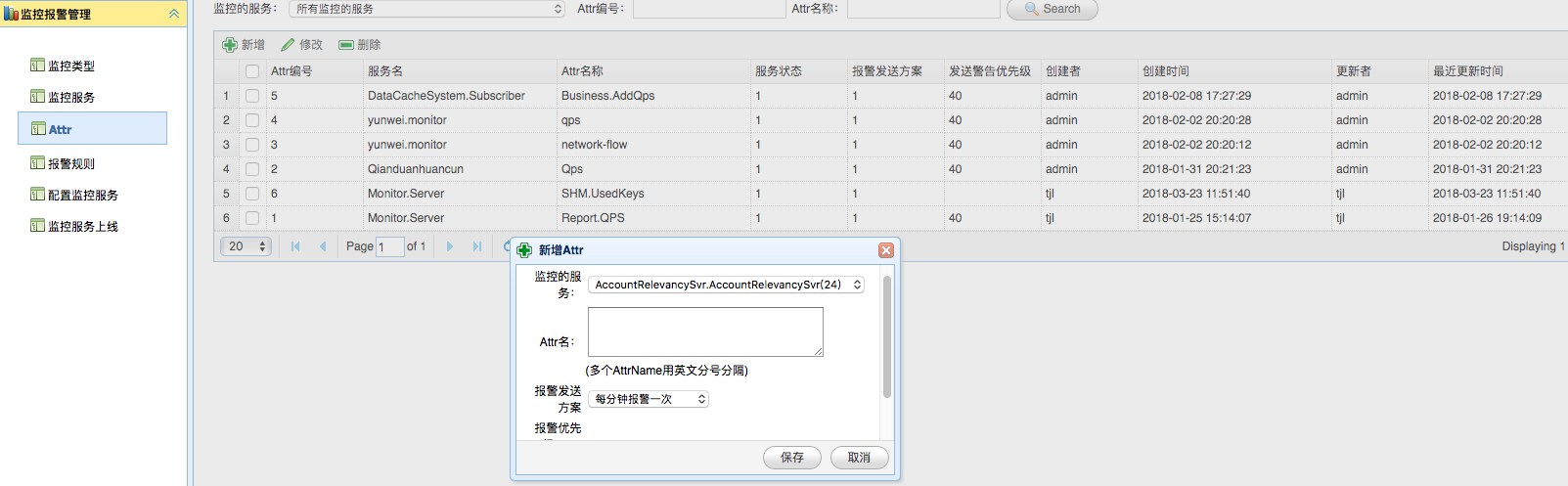
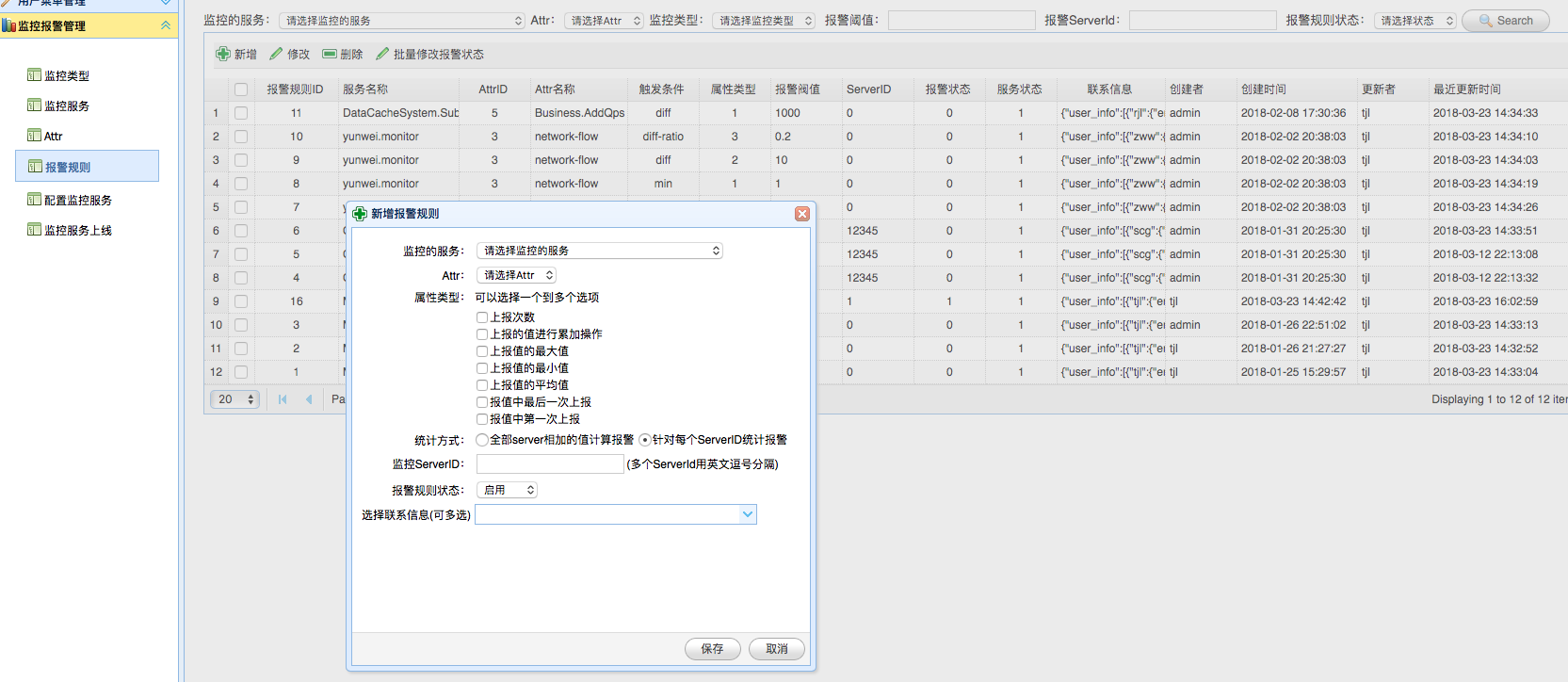
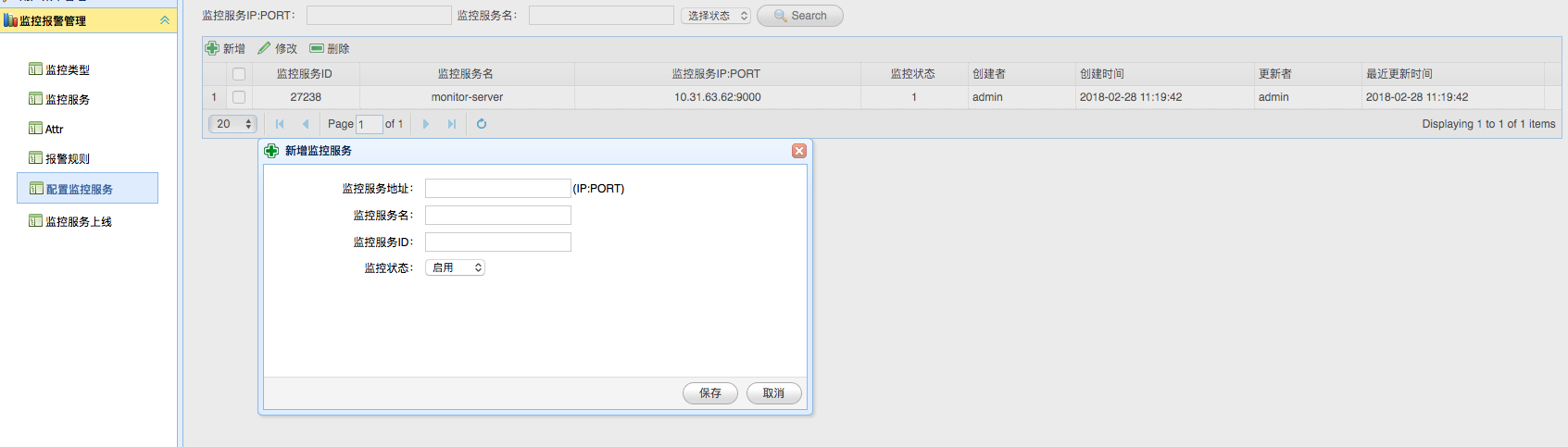
> 此处的服务节点其实是计算中心节点(Judge),此处用于指定一个新计算节点的监听地址、服务ID和其名称。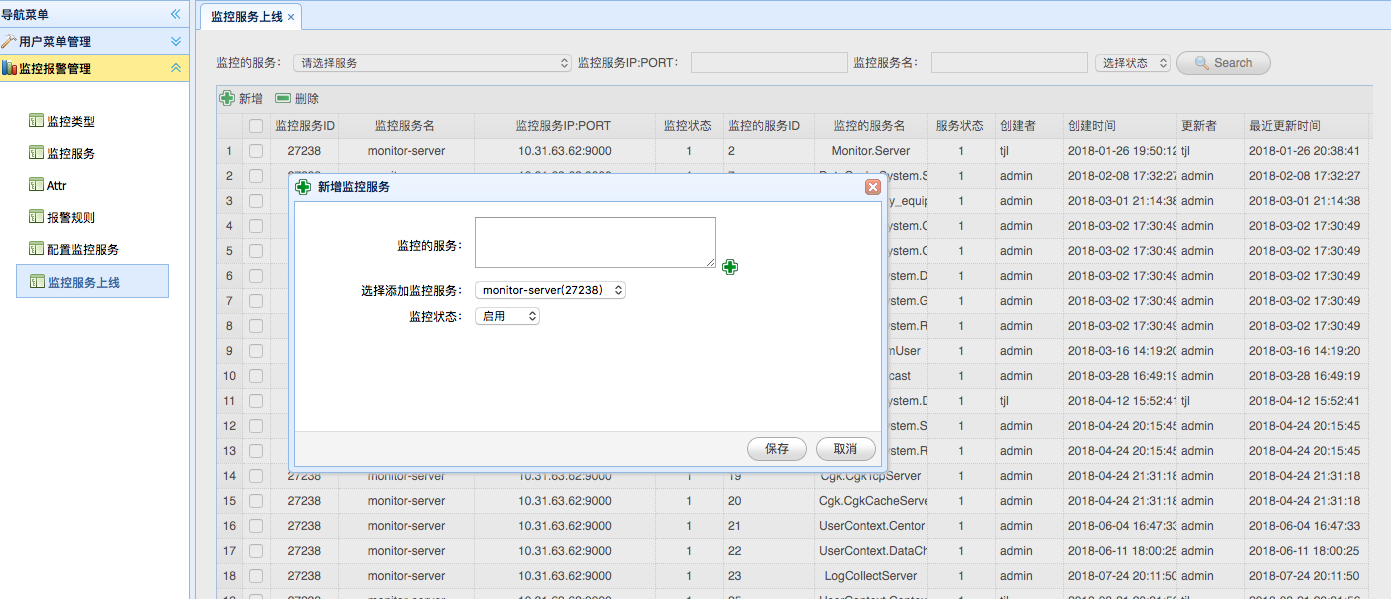
> 所谓服务上线,其实为某个服务指定计算中心节点。
> 从此处也可以看出,当前这套系统缺少一个计算自动调度子系统,整个系统的计算相关的服务治理是通过 Console 此处的控制中心面板人工操作完成的【即第四节工作展望1】。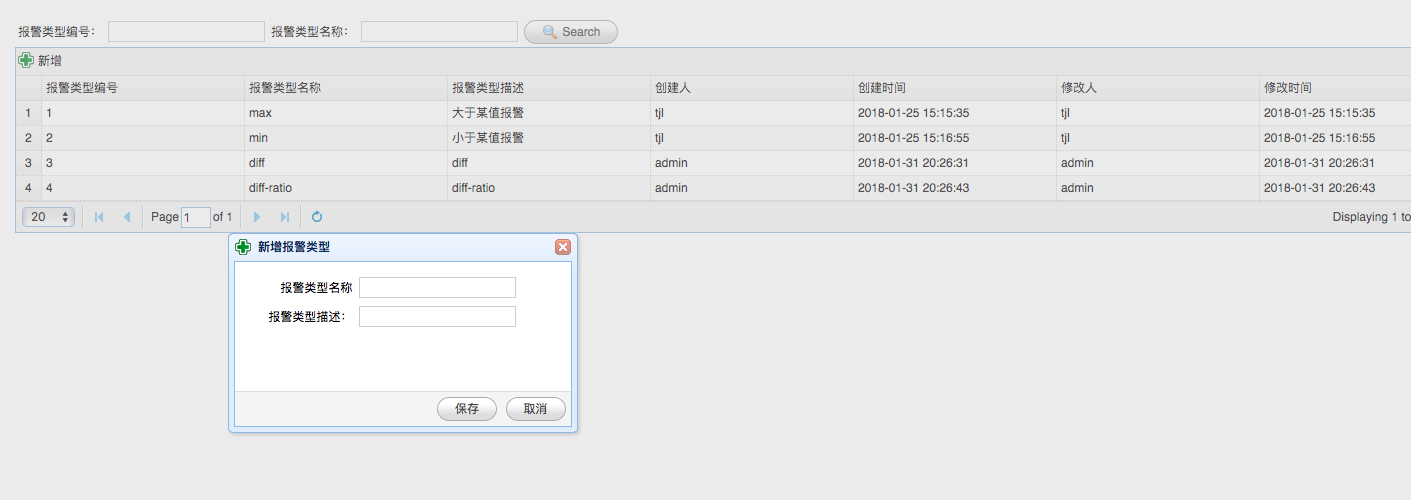
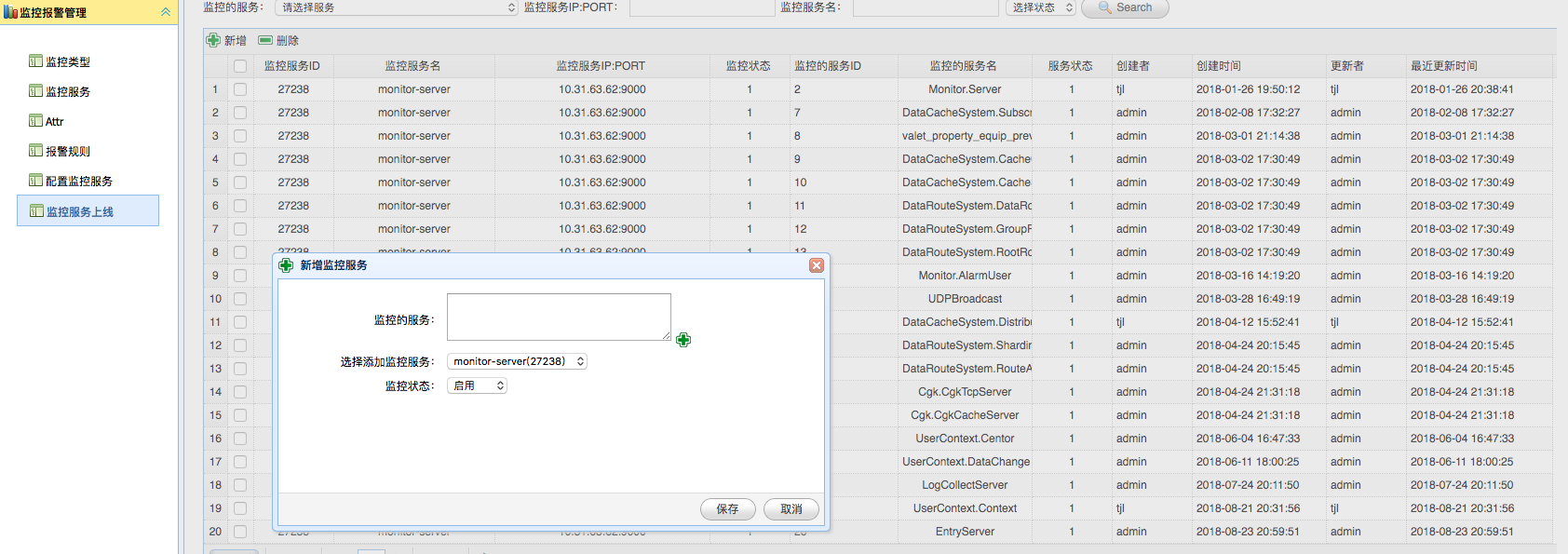
业务上线时,通过添加服务功能把服务相关数据存入 Mysql Service Database 中,并在 Registry 中注册相应的 Schema Key,并把 Judger 节点作为其 Value。
运维人员启用某个 Judger 后,Judger 会定时把自身的 CPU 负载、内存使用量、负责的 Service 列表等 metrics 定时存入 Mysql 中,Console 会监控各个 Judger 的运行情况,并以图表形式展示给运维人员。运维人员上线新服务时,就可以根据这个图表让某个 Judger 负责响应服务的上报结果汇总计算和告警判断。
Monitor 系统作为一种埋点式监控告警服务,具有侵入性,其使用的简易友好程度直接影响了业务开发人员对其接受程度。Monitor 的 Client C++ SDK 接口如下:
/*
监控上报,monitor可统计此接口设置过的累加值、最大值、最小值、平均值以及每n秒内的第一次上报和最后一次上报
@param in service_name 服务名称,最大长度不超过MONITOR_MAX_NAME_LEN,命名规则:【业务名称.服务名称】首字母大些,以点隔开,如:Monitor.MonitorApi
@param in attr_name 属性名称,最大长度不超过MONITOR_MAX_NAME_LEN,命名规则:【模块.监控点】首字母大些,以点隔开,如:MemoryQueue.TotalProcessCount
@param in server_id 服务id
@param in value 上报值
@param in op_mask 上报类型,AlarmType,由 Console 分配
@return
MONITOR_ERR_OK - 成功
其它 - 错误
*/
MONITOR_API int monitor(const char* service_name, const char* attr_name, int64_t server_id, int64_t value, int32_t op_mask);业务人员在调用上面接口时,Client SDK 会补充当前机器的 Host IP、精确到纳秒的时间点等信息后写入基于 SHM 实现的环形队列,其读写形式是多写一读。线上最终实现的队列的指标如下:
即一次写入耗费约 10 微妙,几乎不会影响业务调用方性能。而队列占用了一块大容量内存,Agent 每次读取大概只耗费 0.5 微妙,几乎可以保证业务调用方的每次写入不会因为争抢内存栅栏(一种内存锁)发生阻塞。
Agent 负责收集本机所有 Client 通过 SHM队列 上报的原始监控数据,然后按照一定的路由规则经某个 Proxy 上报给 Service 对应的 Judger,在上报数据流中起着承上启下的作用。
Agent 并不是从队列中读取结果后立即上报。Monitor 的实时单位是分钟级,原始上报结果时间单位是纳秒,Agent 对某指标 Service + Attr + AlarmType + ServerID 以秒级为单位进行聚合(Aggregate)计算。
Agent 从注册中心获取其所在 IDC 的 Clyde 群集,并按照随机路由策略定时地把初步聚合后的数据上报给某个 Clyde 群集中的某个 Proxy。
#3.2 小节中给出了 C++ 形式的 SDK,当其他语言(譬如 Go)的业务系统若要接入 Monitor,便不能使用这套 SDK。Agent 专门启动了一个线程,称之为 Client Puppet Thread,监听一个 Unix Socket 地址,其他语言可以通过 Unix Socket 把上报数据发送给 Client Puppet Thread。Client Puppet Thread 收到数据后写入 SHM 队列,正因为其模拟了 C++ Client 的写入行为,所以称之为 Client Puppet。
Proxy 的作用是接收上报数据,并根据数据中的 Service 字段把数据转发给对应的 Judger,是监控数据中转者。其详细工作流程如下:
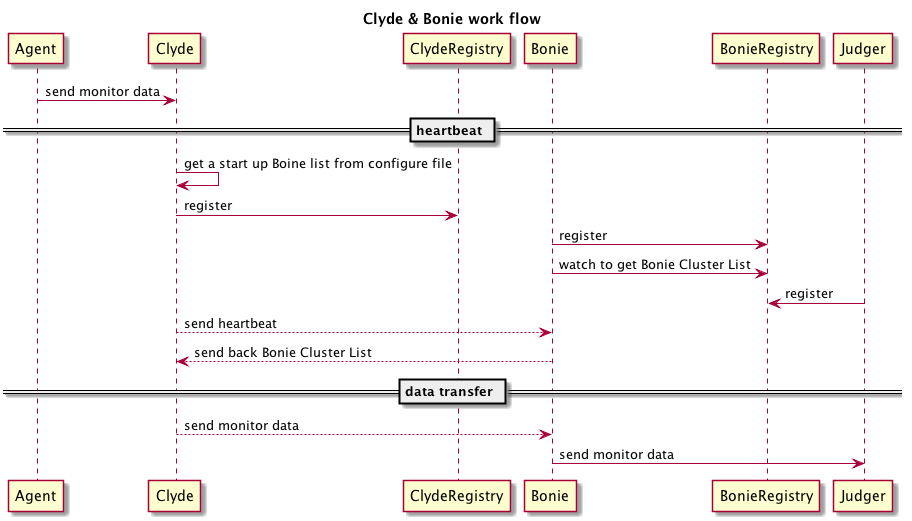
Proxy 启动时根据配置文件获取自身角色(Clyde/Bonnie),如果自身角色是 Clyde 还须加载一个 含有初始 Bonnie 成员列表的配置文件,然后分别向其 IDC 机房的 Registry 注册。
Bonie 启动后向 Registry 注册,并获取其所在群集的所有成员列表。
由于 Clyde 和 Bonie 分别使用不同的 IDC,Clyde 不可能通过 Bonie 所在机房的 Registry 获取 Bonie 群集成员列表,所以每个 Clyde 都有一个初始 Bonie 成员列表配置文件,启动加载配置文件后,依据一定的规则依次向各个 Bonie 发送心跳包,探测出一个可用的 Bonie Proxy 后即固定地与这个 Proxy 进行心跳通信。Bonnie 接收 Clyde 发来的心跳包后,把包括自身在内的 Bonnie 群集成员列表返回给 Clyde。Clyde 定时向 Bonnie 发送心跳包,如果回包中的 Bonnie 群集成员列表与本地缓存中的 Bonnie 群集成员列表有差异,则用最新的 Bonnie 群集成员列表数据更新相应的配置文件。
Bonnie 从 Registry 中获取 Service 与 Judger 之间的映射关系。Bonnie 接收到监控数据网络包并对其拆包(一个上报网络包可能存在多个 Service 的上报数据)后,首先判断每条上报数据是否合法,若不合法(如不存在的 Service 和 Attr)则丢弃不处理,以防止未在 Console 注册的服务向 Monitor 发送监控数据,然后根据 Service 名字分别发往不同的 Judger。
最终线上运行的 Proxy 每秒可转发 20万 的网络包。
如 #2.2 中所述,Judger 职责有:把自身信息注册入 Registry,汇总 Proxy 转发的告警数据存入本地,处理读取告警汇总数据等读请求,告警判断,接收新服务上线通知,把自身运行 metrics 上报到 Console。
Judger 收到 Proxy 转发来的以秒为计时单位数据后,分别计入两个 KV(Service + Attr + AlarmType + AlarmTime + ServerID 和 Service + Attr + AlarmType + AlarmTime)进行计算,同时把这种相对原始的数据通过 Kafka 传输通道存入 Elasticsearch 中。
Judger 对报警数据进行聚合归并计算后的以分钟为计时单位的数据也通过 Kafka 传输通道存入 Dashboard 所使用的 Database InfluxDB 中进行时间序列展示,并依据每个服务的告警条件的参数进行告警判断。如果某 Service 的某个告警判断被触发,则通过告警系统发送告警通知。
最终线上实现的 Judger 每秒可接收 10万 的网络包。
Kafka 作为一种大数据系统常用的 MQ,其作用就是 Monitor 的数据传输通道。
Monitor 的 Kafka Connector 采用 Go 语言实现,依据 Kafka 的 Consumer Group 的消费方式构成了一个群集。
收到 Kafka 消息并解析后,根据数据的不同类型以 Batch 方式分别发往 InfluxDB 群集和 Elasticsearch 群集。
Dashboard 用于从不同维度展示统计结果,是对 Judger 归并计算结果的再加工,其存储依赖时间序列数据库 InfluxDB,展示 Panel 则使用 Grafana。Dashboard 还使用了一个名为 influxdb-timeshift-proxy 的开源组件作为 Grafana Proxy,以实现在 Grafana 同一个 Panel 上聚合对同一 Key 的不同时间维度的数据。
原始的 Dashboard 只用一个 InfluxDB,随着线上汇总数据的增多,数据量已近其极限,
初始版本的 Dashboard 仅仅使用了一个 InfluxDB 作为线上展示数据汇总终点,后来随着数据量的增长,一个 InfluxDB 已然不能承受巨大的数据量,故有必要通过 InfluxDB 集群分散数据压力。而 InfluxDB 集群是收费的,所以愚人就自己撸起袖子通过 一致性Hash 算法攒了一个 InfluxDB 集群,放大的UML架构图如下(其流程与总架构图一致):
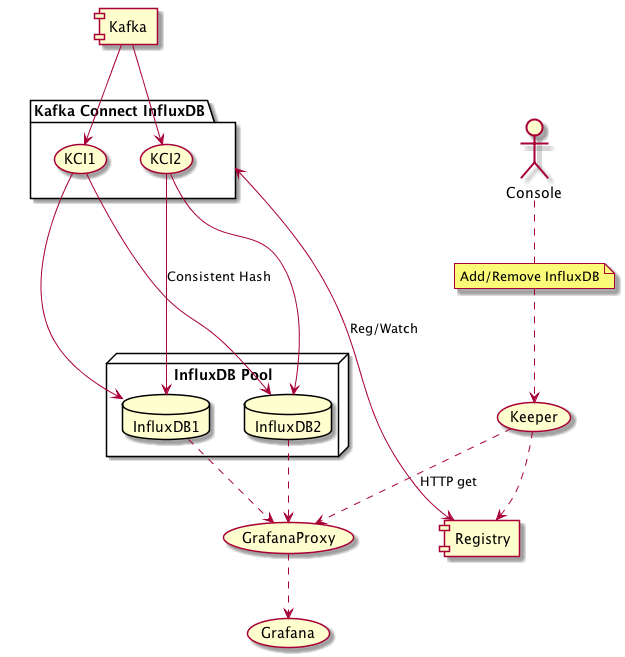
集群中各个成员功能如下:
KCI 实现时候依据 PIPELINE 模式对整个数据传输流程进行了优化:把数据传输过程分解为 **Kafka 消息数据读取**、**Kafka 消息数据解析**、**数据流水写入 InfluxDB**三个步骤,分解后可以分别加大并行处理速度,实现了数据高速地写入 InfluxDB 群集。
Grafana 的强大之处无需愚人庸言,下面分别展示其结合 Monitor 系统后的强大功用。
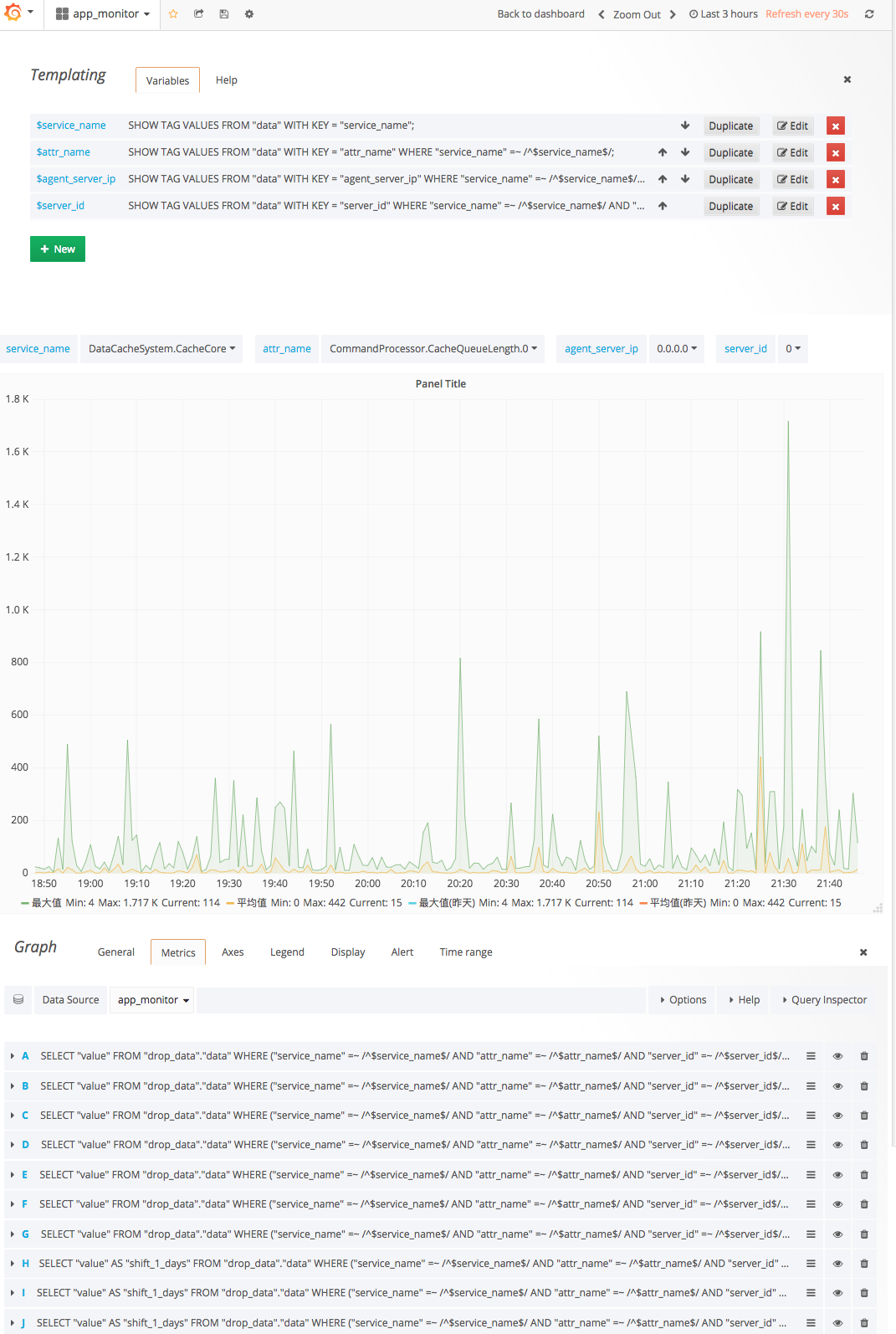
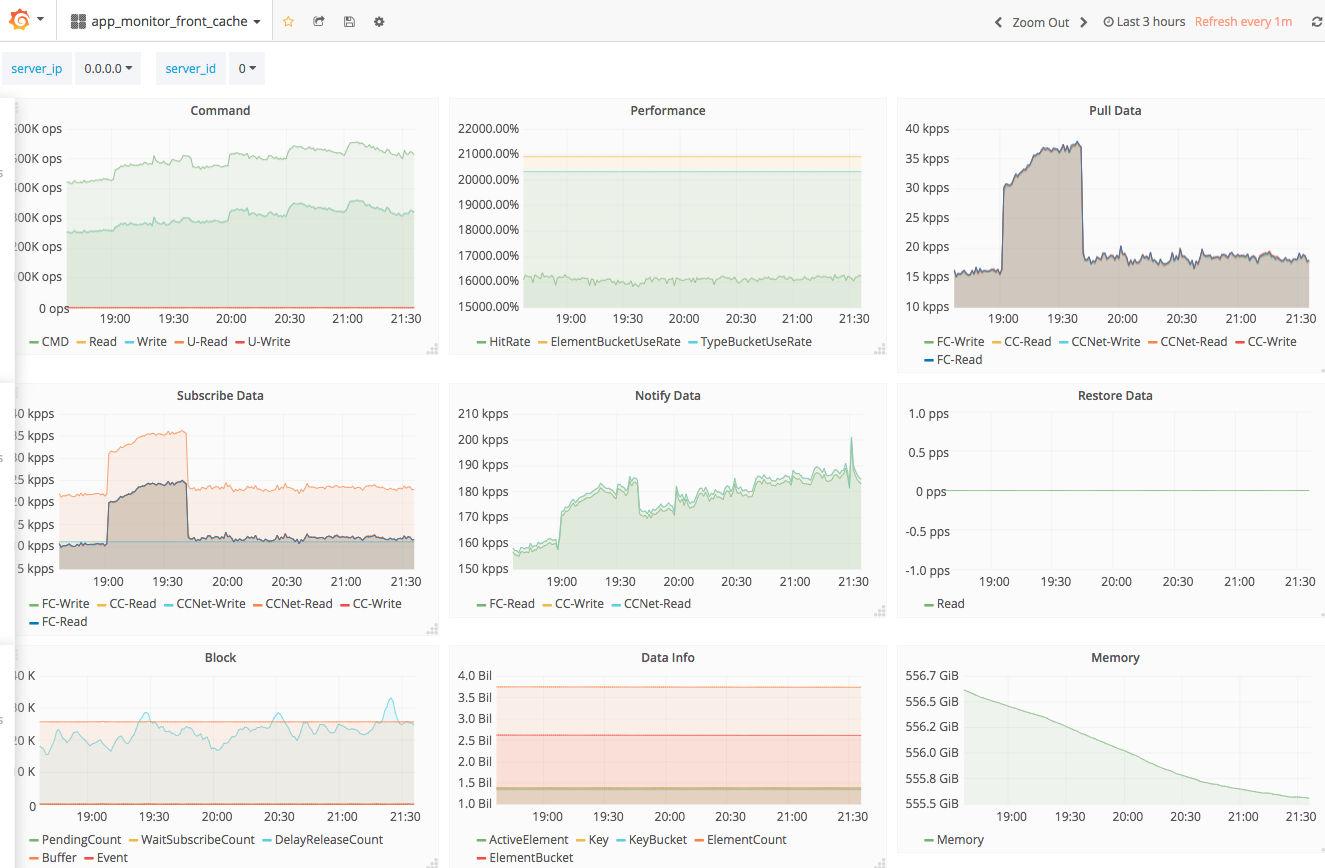
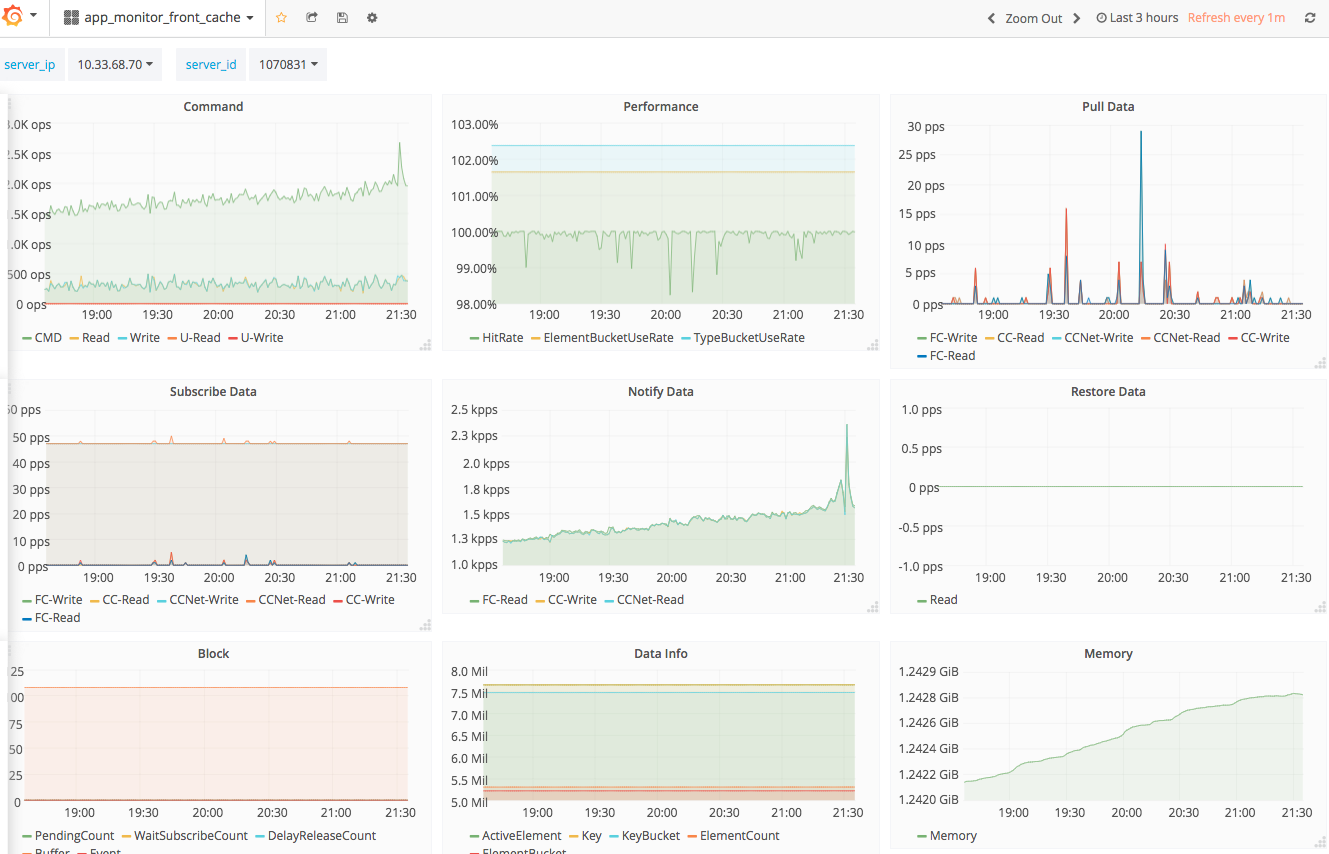
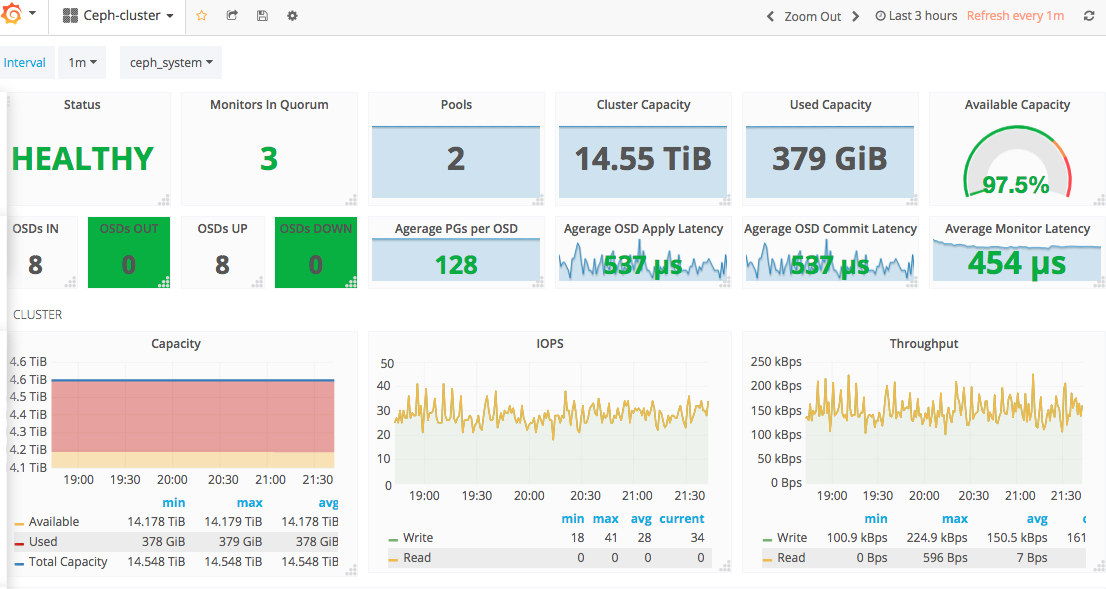
Monitor 系统完成上线后,服务端同事们仅仅使用了 Dashboard 而抛弃了 Alarm,有同事嫌弃设置参数太麻烦,需不断调整,而且即便收到告警也可能及时处理,因为会影响其休息,从一方面也说明了系统尚有许多有待改进之处。
Monitor 系统有待改进的工作如下:
Service + Attr,可以使用数据库中 MySQL 给二者分配的 ID,以减少数据冗余和网络包长度;告警信息延时合并并区分优先级,报警形式多样化;通过故障演练验证报警是否符合预期;

|

|
- 2018/11/17,于雨氏,于丰台,初作此文。
- 2019/02/18,于雨氏,于西二旗,补充 #3.1 Console# 中
服务上线小节相关内容。- 2019/03/16,于雨氏,于黄龙,补充
2.1.1 系统架构设计目标以及2.1.2 计算子升级相关内容。